In this article, we delve into the installation process of Apache Kafka on Ubuntu 24.04 LTS, empowering you to harness its robust streaming capabilities for efficient data handling and processing.
Table of Contents
Prerequisites
- Create Ubuntu Instance 24.04 LTS
- SSH Access with Sudo privileges
- Firewall Port 9092
- JDK 1.8 or higher version
What is Apache Kafka?

Apache Kafka is a distributed streaming platform used for building real-time data pipelines and streaming applications. It’s like a highly efficient and scalable messaging system that can handle large volumes of data in real-time.
Imagine you have a shopping website where users are placing orders. Apache Kafka can be used to capture these order events in real-time and process them, such as updating inventory, sending confirmation emails, and analyzing customer behavior.
In simpler terms, Kafka acts as a central hub where data streams from different sources (like websites, sensors, databases) are collected and processed instantly. It ensures that data is delivered reliably and quickly to the right applications for analysis or action, making it a crucial tool for handling streaming data in modern applications.
Kafka seamlessly integrates three fundamental event streaming capabilities:
- Publish and Subscribe: Producers send event streams to specific topics, while consumers subscribe to these topics to access the events. This architecture enables real-time data flow, decoupling data producers and consumers.
- Storage: Kafka ensures reliable long-term storage by distributing event streams across a cluster of brokers. Events are persisted to disk and replicated for fault tolerance, guaranteeing durability and reliability even during failures.
- Stream Processing: Kafka empowers real-time event stream processing, allowing developers to build applications that handle and analyze event streams instantaneously or historically. It supports operations like filtering, transformation, aggregation, and merging, enabling real-time analytics, event-driven architectures, and reactive applications.
What is Zookeeper?
ZooKeeper is an important component of a Kafka cluster that acts as a distributed coordination service. ZooKeeper is in charge of monitoring and preserving the cluster’s metadata, coordinating the operations of many nodes, and assuring the general stability and consistency of the Kafka cluster.
In a Kafka cluster, ZooKeeper performs crucial tasks:
- Cluster Coordination: ZooKeeper tracks active brokers, their connectivity, and state. Each broker registers with ZooKeeper for discovery by other brokers and clients.
- Controller Election: ZooKeeper facilitates electing a controller node responsible for partition management and cluster metadata.
- Metadata Management: ZooKeeper stores metadata about topics, partitions, leader/follower info, aiding brokers in understanding cluster status.
- Consumer Group Management: ZooKeeper manages consumer groups, storing offsets for each group’s topics to track consumption progress.
- Notifications and Watchers: ZooKeeper’s Watchers feature allows clients to receive alerts for specific events, aiding in real-time coordination.
Kafka Ecosystem
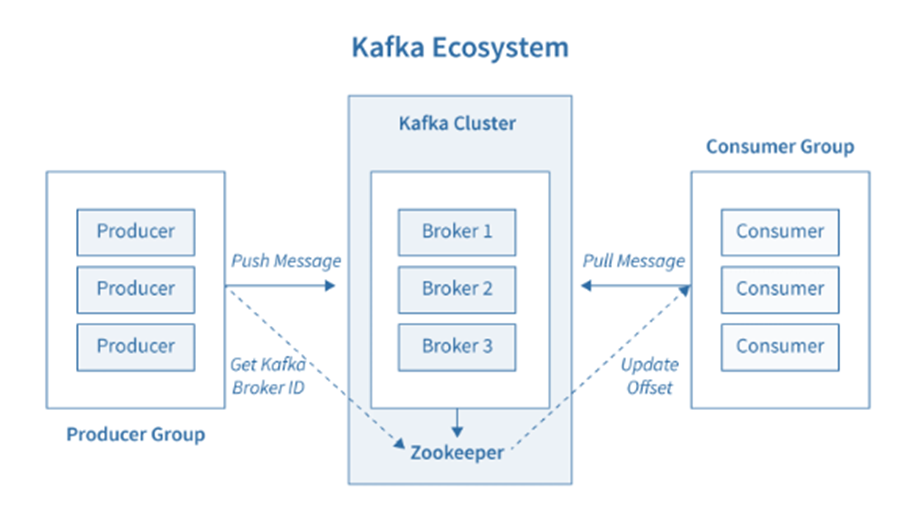
- Producers are applications that publish messages to topics in Kafka.
- Topics are categories or feeds that hold related messages.
- Brokers are servers that store messages published by producers. Producers send messages to brokers and consumers receive messages from brokers.
- Consumers are applications that subscribe to topics and receive messages from them. A consumer group is a group of consumers that subscribe to a topic and collectively process the messages. Each message is assigned a unique offset, a number that represents its position within a topic partition. When a consumer joins a consumer group, it starts consuming messages from the offset it was assigned. This allows multiple consumers to consume messages from the same topic without duplicates or missing messages.
- Zookeeper is a coordination service that helps Kafka maintain consistency across the cluster. It keeps track of the brokers, topics, and consumers in the cluster, and it helps to elect a leader broker for each topic partition.
In short, producers send messages to topics, brokers store the messages, and consumers subscribe to topics to receive the messages. Zookeeper helps to keep everything in sync.
Apache Kafka Use Cases
- Real-time Data Processing:
- Example: Financial institutions use Kafka to process and analyze stock market data in real-time for trading decisions.
- Event Streaming Architectures:
- Example: E-commerce platforms use Kafka to stream user interactions like product views, purchases, and cart updates for real-time analytics and personalization.
- Log Aggregation and Monitoring:
- Example: Tech companies use Kafka to aggregate and centralize logs from distributed systems for monitoring, troubleshooting, and analysis.
- Microservices Communication:
- Example: Large-scale applications use Kafka as a message broker for communication between microservices, ensuring scalability and fault tolerance.
- IoT Data Integration:
- Example: Smart cities use Kafka to integrate and process data from IoT devices like sensors, cameras, and meters for real-time monitoring and decision-making.
- Machine Learning Pipelines:
- Example: Data-driven companies use Kafka to build machine learning pipelines, streaming data from sources to models for training and inference.
- Real-time Recommendations:
- Example: Streaming platforms use Kafka to deliver personalized content recommendations based on user behavior and preferences.
- Fraud Detection and Security Monitoring:
- Example: Financial institutions use Kafka to detect anomalies and potential fraud in real-time by analyzing transaction data streams.
Apache Kafka’s Advantages and Disadvantages
Advantages:
- High-speed, low-latency: Handles massive data streams with minimal delay.
- Fault-tolerant and durable: Ensures data isn’t lost during failures.
- Scalable: Grows as your data needs grow.
- Real-time processing: Ideal for building real-time data pipelines.
- Reduces integration complexity: Single point of connection for data producers and consumers.
Disadvantages:
- Limited monitoring tools: Requires additional setup for comprehensive monitoring.
- Performance impact of message modification: Modifying messages can slow Kafka down.
- No wildcard topic selection: Subscriptions require exact topic names.
- Resource usage with large queues: Managing a high number of queues can impact performance.
- Missing message paradigms: Lacks certain messaging patterns like request/reply.
Apache Kafka Applications
- Uber: Connects riders and drivers for real-time matching.
- Twitter: Achieves significant cost savings (up to 75%) on high-volume data streams with Kafka’s efficiency.
- Netflix: Utilizes Kafka’s “Keystone Pipeline” for real-time data processing and cost-effective data delivery.
- Oracle: Leverages Kafka for reliable data streaming between Oracle databases and applications.
- Mozilla: Employs Kafka to back up data and plans to use it for collecting user telemetry.
- LinkedIn: (Kafka’s Birthplace) This messaging system forms the core of LinkedIn’s infrastructure, powering message consumption in products like LinkedIn Today and Newsfeed.
Steps for Installing Apache Kafka on Ubuntu 24.04 LTS
Step#1:Install OpenJDK on Ubuntu 24.04 LTS
To update system packages
sudo apt-get update
you can install OpenJDK 8 or OpenJDK 11
sudo apt install default-jdk
To check the java version, Here I have install installed Oracle Java 11 on my system.
java -version
Output:

Step#2:Install Apache Kafka on Ubuntu 24.04 LTS
To download the Kafka binary from offical website. Please use this Kafka official download page and to prompts to download page and you can download Kafka using wget
sudo wget https://downloads.apache.org/kafka/3.7.0/kafka_2.12-3.7.0.tgz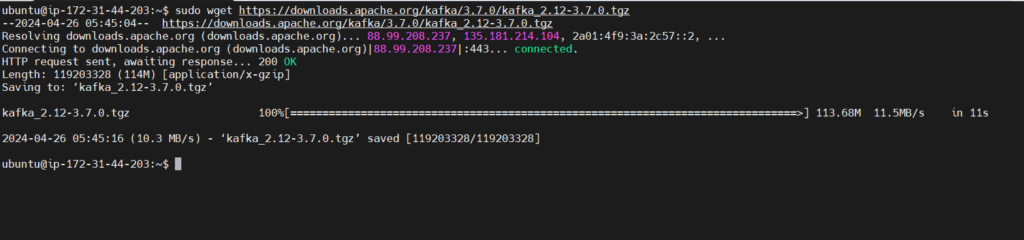
Now to un-tar or Unzip the archive file and move to another location:
sudo tar xzf kafka_2.12-3.7.0.tgz
sudo mv kafka_2.12-3.7.0 /opt/kafka

Step#3:Creating Zookeeper and Kafka Systemd Unit Files in Ubuntu 24.04 LTS
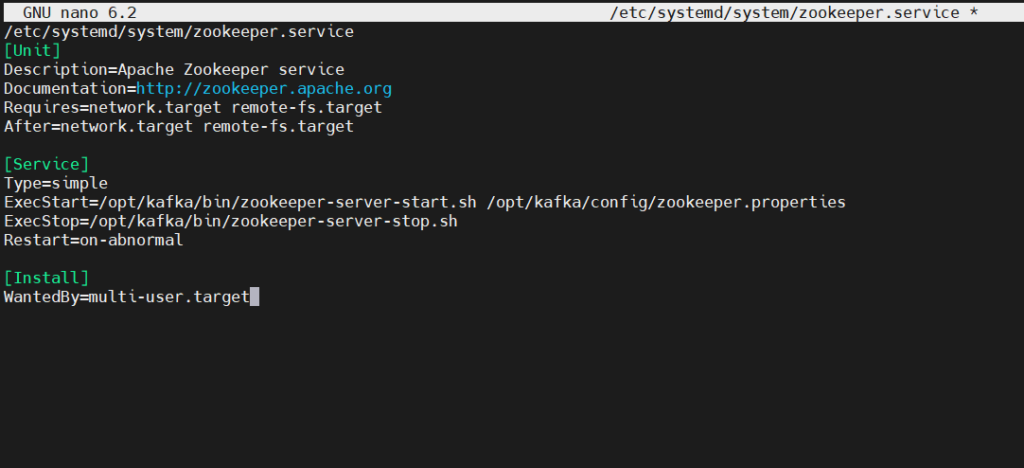
Create the systemd unit file for zookeeper service
sudo nano /etc/systemd/system/zookeeper.service
paste the below lines
/etc/systemd/system/zookeeper.service
[Unit]
Description=Apache Zookeeper service
Documentation=http://zookeeper.apache.org
Requires=network.target remote-fs.target
After=network.target remote-fs.target
[Service]
Type=simple
ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties
ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
Reload the daemon to take effect
sudo systemctl daemon-reload
Create the systemd unit file for kafka service to start and restart the kafka service
sudo nano /etc/systemd/system/kafka.service
paste the below lines
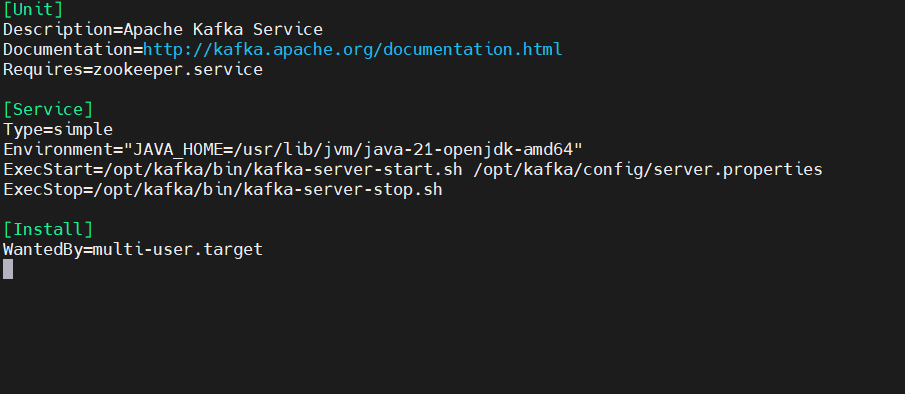
[Unit]
Description=Apache Kafka Service
Documentation=http://kafka.apache.org/documentation.html
Requires=zookeeper.service
[Service]
Type=simple
Environment="JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64"
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
[Install]
WantedBy=multi-user.target
Reload the daemon to take effect
sudo systemctl daemon-reload
Lets start kafka service first
sudo systemctl start kafka
Check the status of kafka service if it started
sudo systemctl status kafka
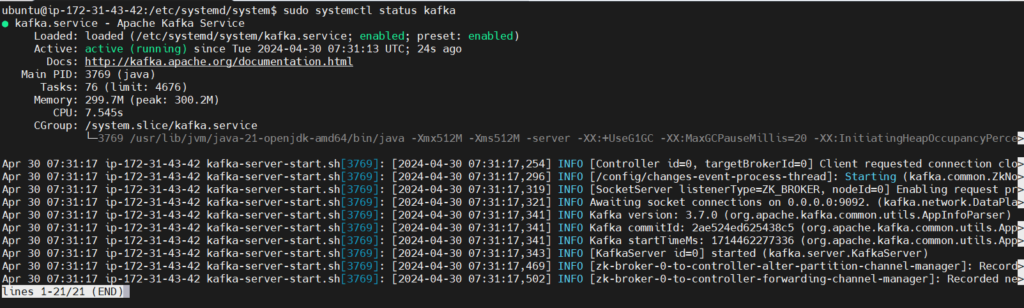
Step#4:To Start ZooKeeper and Kafka Service and Check its Status
Lets start zookeeper service first
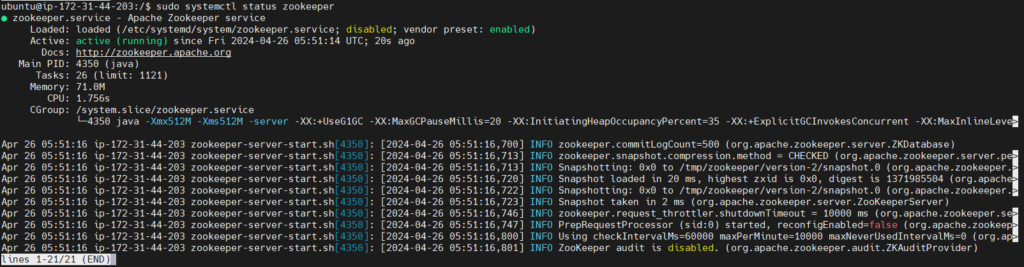
sudo systemctl start zookeeper
Check the status of zookeeper service if it started
sudo systemctl status zookeeper
Output:
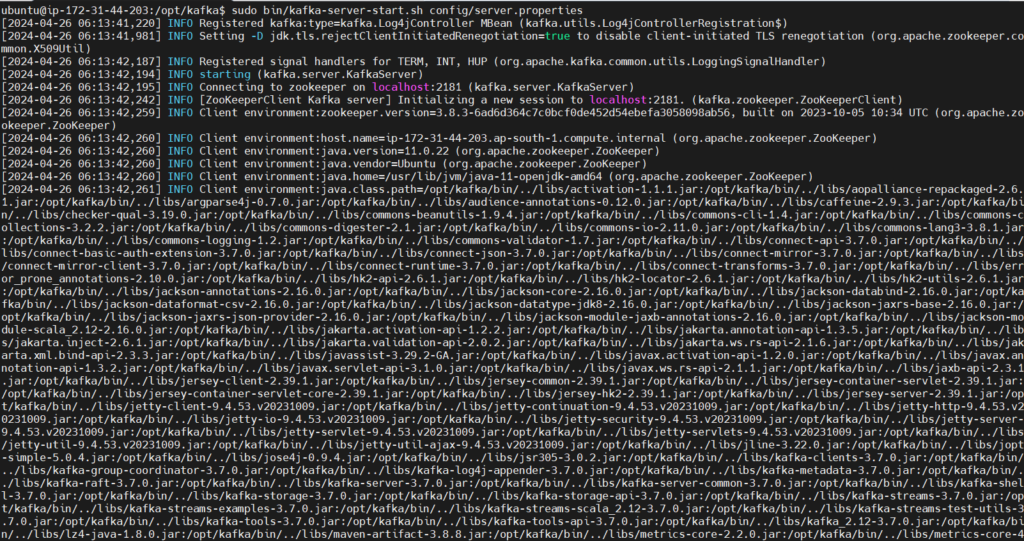
Start the kafka service
sudo bin/kafka-server-start.sh config/server.properties
Output:
Step#5:Creating Topic in Kafka
Now we will create a topic named as “DevOps” with a single replicaton-factor and partition:
cd /opt/kafka
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic DevopsHint
Output:

Explanation of command
- –create :- It is used for create a new topic
- –replication-factor :- It is used for how many copies of data will be created.
- –partitions :- It is used for set the partitions options as the number of brokers you want your data to be split between.
- –topic :- It is used for name of the topic
To check the list of topics created.
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
Output:

Step#6:To send some messages using Kafka
To send some messages for created Topic.
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic DevopsHint
its prompt for messages to type:
> hello world! > How are you? > This is DevopsHint > Bye…
Step#7:To Start consumer in Kafka
Using below command we can see the list of messages:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic DevopsHint --from-beginningOutput

Step#8:To Delete any Topics in Kafka
If you want to delete any created topic use below command:
bin/kafka-topics.sh --delete --bootstrap-server localhost:9092 --topic DevopsHint
We have covered How to Install Apache Kafka on Ubuntu 24.04 LTS.
Conclusion:
In conclusion, this guide has outlined the simple steps to install Apache Kafka on Ubuntu 24.04 LTS, empowering you to leverage its capabilities for efficient real-time data processing and streaming applications.
Reference:-
For reference visit the official website .
Any queries pls contact us @Fosstechnix.com.
Related Articles: